
Ada Lovelace‘s portrait, first programmer in the history of computers. Autor: William Henry Mote, 1838. Source: The Ada Picture Gallery.
The use of the Internet has spread further than computers and beyond the bounds of any specific discipline, and has come to permeate the texture of our reality and every aspect of our daily lives. The ways in which we relate to each other, obtain information, make decisions… that is, the ways in which we experience and learn about our surroundings, are increasingly mediated by the information systems that underlie the net. Massive amounts of information are generated by this constant interaction, and the only way to manage this data is through automated processing using algorithms. A humanist understanding of how this ‘algorithmic medium’ has evolved and how we interact with it is essential in order to ensure that citizens and institutions continue to play an active role in shaping our culture.
A young information and financial tycoon heads across Manhattan in a limousine in the first scene of David Cronenberg’ most recent film Cosmopolis, based on a novel by Don DeLillo. During the ride, Eric Packer monitors the flow of information that flashes up on screens as he leads us on a quest for a new perspective. His encounters with various characters and the sights and sound of the city that enter through the windows offer us a glimpse into the inner workings, consequences, and gaps of what the film calls ‘cyber-capitalism’. The journey ends with a confrontation between the protagonist –whose fortune has been wiped out in the course of the day by erratic market behaviour that his algorithms were unable to predict– and his antithesis, a character who is unable to find his place in the system.
The interplay between technology and capital – the computerised processing of bulk data in order to predict and control market fluctuations – is one of the constants of capitalist speculation. In fact, 65% of Wall Street transactions are carried out by ‘algo trading’ software. In a global market where enormous amounts of data are recorded and a rapid response rate gives you an edge over the competition, algorithms play a key role in analysis and decision-making.
Similarly, algorithms have found their way into all the processes that make up our culture and our everyday lives. They are at the heart of the software we use to produce cultural objects, through programmes that are often freely available in the cloud. They also play a part in disseminating these objects through the net, and in the tools we use to search for them and retrieve them. And they are now essential for analysing and processing the bulk data generated by social media. This data is not only produced by the ever-increasing amount of information posted by users, but also by tracking their actions in a network that has become a participatory platform that grows and evolves through use.
An algorithm is a finite set of instructions applied to an input, in a finite number of steps, in order to obtain an output – a means by which to perform calculations and process data automatically.
The term ‘algorithm’ comes from the name of the 9th century Persian mathematician al-Khwarizmi, and originally referred to the set of rules used to perform arithmetic operations with Arabic numerals. The term gradually evolved to mean a set of procedures for solving problems or performing tasks. It was Charles Babbage who made the connection between algorithms and automation with his hypothesis that all the operations that play a part in an analysis could be performed by machines. The idea was that all processes could be broken down into simple operations, regardless of the problem being studied. Although Babbage designed his Differential Engine and Ada Lovelace created the first algorithm for his Analytical Engine, it was Alan Turing who put forward the definitive formalisation of the algorithm with his Universal Machine in 1937. Turing’s theoretical construct is a hypothetical device that manipulates symbols on a strip of tape according to a table of rules, and can be adapted to simulate the logic of any computer algorithm. The advent of the Internet took this logical construct beyond the computer. Internet protocol (1969) and the web (1995) became a kind of universal container in which data could be stored, accessed and processed on any computer. These developments, along with the convergence that went hand in hand with the boom in personal computing in the eighties, meant that computation – numerical calculation – spread to all digitalised processes. Meanwhile, URLs allowed algorithms to interact and interconnect amongst themselves, eventually producing what Pierre Lévy calls the ‘algorithmic medium’: the increasingly complex framework for the automatic manipulation of symbols, which would become the medium in which human networks collaboratively create and modify our common memory.
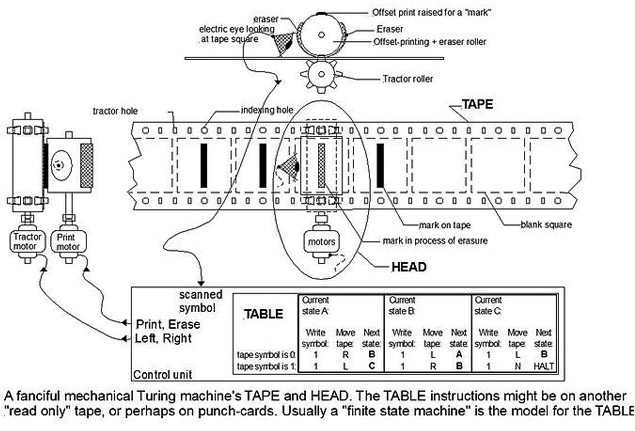
Turing Machine. Source: Wikimedia Commons.
Algorithms play a part in all our everyday interactions with the social web. With 699 million users connecting each day, popular social networking site Facebook is working on the problem of how to display the updates of the many friends, groups and interests that its users can follow. Its answer is the algorithm known as EdgeRank, which processes data about our interests – our ‘likes’ –, the number of friends we have in common with the person posting a news item, and the comments posted on it, in order to prioritise what we see on our news feed and hide the ‘boring’ stories. The algorithm also tracks the graph of our contacts in order to suggest new friends.
Twitter similarly uses algorithms to suggest new accounts to follow, and to create content of the Discover tab and update its trending topics. In this case the complex algorithm doesn’t just work out what word is tweeted most often, it also calculates whether the use of a particular term is on the rise, whether it has been a trending topic before, and whether it is used among different networks of users or just one densely connected cluster. It does this by monitoring the ‘hashtags’ that interconnect all the tweets it appears in, which were introduced by Twitter in 2007 and have since spread throughout social media sites. It also uses URL shortening service or t.co (f.bo in Facebook), which is generated every time we use a social button to share a URL. These do not just minimise the number of characters in a post, but also transform links into data-rich structures that can be tracked in order to find out how they are shared no the platform and build up profiles of their users.
As well as social networks, the social web also includes all kinds of platforms that allow us to create and share information, including online publishing services such as blogs, recommendation systems like Digg and Reddit and search engines. All of these platforms rely on algorithms that work with specific criteria. The search engine Google, for example, which has to work in a medium consisting of more than 60 trillion pages, in which more than 2 million searches are carried out every minute, is based on the premise that “you want the answer, not trillions of webpages.” In this scenario keyword indexing is not enough, so Google’s PageRank algorithm imitates user behaviour by monitoring the links to and from every page, and then ranks the pages, displaying the most relevant results first. The algorithm also works in conjunction with others that process our search history, our language, and our physical location in order to customise the results.
Algorithms also process data generated by our online actions to suggest what books we should buy on Amazon, what videos we should watch on YouTube, and to determine the advertisements we will be shown on all these platforms. Aside from these algorithms that we regularly interact with, there are others such as Eigenstaste, a collaborative filtering algorithm for rapid computation of recommendations developed at UC Berkeley; an algorithm recently developed at Cornell and Carnegie Mellon Universities that reconstructs our life histories by analysing our Twitter stream; and the algorithm developed at Imperial College London to reduce Twitter spam by detecting accounts that are run by bots instead of humans. The growing presence of algorithmics in our culture is reflected in the #algopop tumblr, which studies the appearance of algorithms in popular culture and everyday life.
The examples mentioned here illustrate how information on the Internet is accessed and indexed automatically, based on data drawn from our online behaviour. Our actions generate a flow of messages that modify the inextricable mass of interconnected data, subtly changing our shared memory. This means that communication in the ‘algorithmic medium’ is ‘stigmergic’, which means that individuals alter the actual medium when they communicate in it. Every link that we create or share, every time we tag something, every time we like, search, buy or retweet, this information is recorded in a data structure and then processed and used to make suggestions or to inform other users. As such, algorithms help us to navigate the enormous accumulation of information on the net, taking information generated individually and processing it so that it can be consumed communally. But when algorithms manage information, they also reconstruct relationships and connections, they encourage preferences and produce encounters, and end up shaping our contexts and our identities. Online platforms thus become automated socio-technical environments.

Charles Babbage’s Analytical Engine on display at the King George III Museum, 1844. Source: Wikimedia Commons.
The use of automation in our culture has epistemological, political and social consequences that have to be taken into account. For example, the continuous monitoring of our actions transforms our existing notions of privacy; algorithms make us participate in processes that we are not conscious of; and although they increase our access to information – such enormous amounts of it that it is no longer humanly discernible – and boost our agency and our capacity to choose, they are by no means neutral and they can also be used for the purposes of control.
Most users see the net as a broadcast medium, like traditional media, and are not aware of how information is filtered and processed by the medium. Not only are the effects of algorithms imperceptible, and often unknown because they are in the hands of commercial agencies and protected by property laws, they have also become inscrutable, because of the interrelation between complex software systems and their constant updates.
Furthermore, algorithms are not just used for data analysis, they also play a part in the decision-making process. This raises the question of whether it is justifiable to accept decisions made automatically by algorithms that do not work transparently and cannot be subject to public debate. How can we debate the neutrality of processes that are independent of the data they are applied to? Also, when algorithms analyse the data compiled from our earlier actions they are strongly dependent on the past, and this may tend to maintain existing structures and limit social mobility, hindering connections outside of existing clusters of interests and contacts.
Given that these algorithms influence the flow of information through the public sphere, we need to come up with metaphors that make these processes understandable beyond the realm of computer experts. We need to make them understandable to people in general, so that everybody can participate in discussions about what problems can be solved algorithmically and how to approach these problems. Encouraging participation is a way to ensure the ecological diversity of the medium and its connection to pragmatics.
Software studies pioneer Matthew Fuller points out that even though algorithms are the internal framework of the medium in which most intellectual work now takes place, they are rarely studied from a humanistic or critical point of view, and are generally left to technicians. In his book Behind the Blip: Essays on the Culture of Software, Fuller suggests some possible critical approaches, such as: running information systems that really reveal their functioning, structure and conditions; preserving the poetics of connection that is inherent to social software or promoting use that always exceeds the technical capacities of the system; and encouraging improbable connections that enrich the medium with new potential and broader visions that allow room for invention.
Some initiatives along these lines are already occurring in the ‘algorithm medium’, actively contributing to the use of computing by non-experts and allowing user communities to influence its course. They include data journalism, which creates narratives based on data mining; free software, developed in collaboration with its users; crowdsourcing initiatives based on data that is obtained consciously and collaboratively by users; and the rise in the communal creation of MOOCs (massive open online courses).
On another front, cultural institutions also need to develop a presence in the virtual medium. By allowing online access to their archives, data, know-how and methodology, projects, and collaborators, they can promote new interests and connections, taking advantage of ‘stigmergy’ to boost the diversity and poetics of the medium. Similarly, workshops such as those organised as part of the CCCB’s Internet Universe project help to promote a broader understanding and awareness of this medium, and encourage greater and more effective participation.
The capacity and the scope of the algorithmic environment is now being strengthened through the use of artificial intelligence technology, as illustrated by Google’s ‘Hummingbird’ semantic algorithm – which is based on natural language processing – and Mark Zukenberg’s mission to ‘understand the world’ by analysing the language of posts shared on Facebook. It is important to encourage critical, public debate about the role of these mechanisms in shaping our culture if we want to ensure the continuing diversity and accessibility of the net.





{kind=link}
adolflow | 03 March 2014
Interesantísimo, gran resumen.
Un detalle, la imagen de NotaG ya no está disponible:
http://commons.wikimedia.org/wiki/File:Representaci%C3%B3n_de_un_programa_de_ordenador_para_la_m%C3%A1quina_anal%C3%ADtica.png
Equip CCCB LAB | 03 March 2014
Gracias. Ya hemos quitado la imagen de “Nota G”
Oriol Abad Hogeland | 13 March 2014
Un control és un negoci.
Leave a comment