
Retrato de Ada Lovelace, primera programadora de la historia de las computadoras. Autor: William Henry Mote, 1838. Fuente: The Ada Picture Gallery.
El uso de Internet se ha extendido, más allá de los ordenadores y de cualquier ámbito específico, infiltrándose en la textura de nuestra realidad y en todos los aspectos de nuestra vida cotidiana. El modo en que nos relacionamos, nos informamos, tomamos decisiones… en definitiva, conocemos y experimentamos nuestro entorno, está cada vez más mediatizado por los sistemas de información que conforman esta red. Esta interacción constante da lugar a una producción masiva de información que solo puede ser gestionada de modo automatizado, mediante la aplicación de algoritmos. Comprender cómo se ha formado y cómo interactuamos con este «medio algorítmico», desde un enfoque humanístico, es indispensable para que tanto los ciudadanos como las instituciones mantengan un papel activo en la conformación de nuestra cultura.
Un joven magnate de la información y las finanzas se dispone a cruzar Manhattan en limusina. Así empieza Cosmopolis, la última película de David Cronenberg, basada en la obra de Don DeLillo. Durante la travesía, Eric Packer analiza el flujo de informaciones dispensado por pantallas, mientras nos lleva a la búsqueda de una nueva perspectiva. El encuentro con distintos personajes, así como la irrupción de la ciudad y sus ruidos a través de las ventanillas, nos dejan ver los entresijos, las consecuencias y los intersticios de lo que en el film es denominado cibercapitalismo. El viaje finaliza con el enfrentamiento del protagonista –arruinado ante un comportamiento errático del mercado que los bellos números de sus algoritmos no pueden prever– con su personaje antitético, alguien que no encuentra encaje en el sistema.
La interacción de tecnología y capital, es decir, el procesamiento automático de datos masivos para la previsión y el control de las fluctuaciones del mercado, es una constante de la especulación capitalista. En efecto, en Wall Street un 65% de las operaciones son llevadas a cabo por programas de «algo trading». En un mercado global, donde se registran grandes masas de datos y donde una respuesta rápida supone una ventaja sobre la competencia, los algoritmos tienen un papel predominante tanto en el análisis como en la toma de decisiones.
Ahora bien, los algoritmos también se han ido infiltrando en todos los procesos que conforman nuestra cultura y vida cotidiana. Conforman el software que usamos para producir objetos culturales, programas que muchas veces se ofrecen de forma libre en la nube. Asimismo, operan en la distribución de estos objetos a través de la red y en la búsqueda y recuperación de los mismos por parte de los usuarios. Finalmente, se han hecho necesarios para el análisis y procesamiento de los datos masivos que produce la web social. Datos no solo referidos al siempre creciente número de aportaciones, sino también obtenidos del seguimiento de las acciones de los usuarios, en una web que se ofrece como plataforma para la participación y que crece y evoluciona con el uso.
Un algoritmo es una lista finita de instrucciones que se aplican a un input durante un número finito de estados para obtener un output, permitiendo realizar cálculos y procesar datos de modo automático.
La expresión algoritmo procede del nombre del matemático persa del siglo IX al-Khal-Khwarizm y al principio hacía referencia al conjunto de reglas para desarrollar operaciones aritméticas con números árabes. Este término fue evolucionando para definir un conjunto de reglas para ejecutar una función. La relación de esta expresión con la automatización se debe a Babbage y su hipótesis según la cual el total de operaciones envuelto en el desarrollo de un análisis podía ser ejecutado por máquinas. A este fin, todo proceso debía dividirse en operaciones simples e independientes de la realidad a procesar. A pesar del desarrollo de su máquina diferencial y la propuesta por parte de Ada Lovelace del primer algoritmo para ser desarrollado en una máquina, fue Alan Turing quien, en 1937, propuso la formalización definitiva del algoritmo con su máquina universal. El constructo teórico de Turing consta de un aparato hipotético que manipula signos en una cinta de acuerdo con una tabla de reglas definidas, y puede ser aplicado al análisis de la lógica interna de cualquier ordenador. El advenimiento de Internet supondrá la salida de este esquema lógico del ordenador. El protocolo Internet (1969) y la invención de la web (1995) permitieron un contenedor universal, donde los datos podían ser almacenados, accedidos y procesados desde cualquier ordenador. Esto, junto con la convergencia ligada al desarrollo de la informática personal en los años ochenta, llevaría a extender la computación, el cálculo numérico, a cualquier proceso digitalizado. Al mismo tiempo, los algoritmos, gracias a las URL, podían interactuar y conectarse entre ellos. Esto dará lugar a lo que Pierre Lévy denomina «medio algorítmico». Una estructura cada vez más compleja de manipulación automática de símbolos que pasará a constituir el medio donde las redes humanas construyen y modifican, de modo colaborativo, su memoria común.
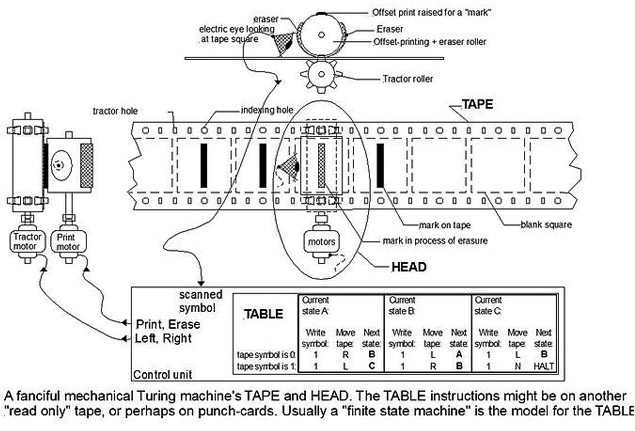
Máquina de Turing. Fuente: Wikimedia Commons.
Los algoritmos operan en todas nuestras interacciones cotidianas con la web social. La conocida red social Facebook, a la que se conectan 699 millones de usuarios cada día, se plantea el problema de cómo mostrar las actualizaciones de los múltiples amigos, grupos e intereses que la red permite seguir. La solución a esta cuestión es Edgerank. Este algoritmo analiza los datos recopilados acerca de nuestros intereses –los «me gusta» que pulsamos–, el número de amigos que tenemos en común con el emisor de la historia, así como los comentarios realizados, para determinar qué post mostrar en nuestro «news feed» y ocultar las historias «aburridas». Del mismo modo, es un algoritmo el que rastrea el grafo de nuestros contactos para sugeriros nuevos amigos.
Twitter procede de modo similar a la hora de sugerirnos nuevas cuentas que seguir, elaborar el contenido de la pestaña «descubre» o la lista de los «trend topics». En este último caso, trabaja un complejo algoritmo que no se limita a contabilizar la palabra más twitteada, sino que tiene en cuenta si un término se ha acelerado en su uso, si ha sido tendencia anteriormente, o si este es usado en diferentes redes o solo dentro de un cluster densamente conectado de usuarios. A este fin, el algoritmo no solo cuenta con el seguimiento de los «hastags», la etiqueta que permite linkear con todas las historias que la contienen –propuesta en 2007 por esta plataforma y que ha extendido su uso a toda la web social–, sino que cuenta también con la tecnología de los links abreviados. Los t.co (f.bo, en el caso de Facebook) se generan cada vez que compartimos una web a través de un botón social. Estos permiten no solo economizar el número de caracteres, sino que convierten los links en estructuras ricas en datos, que permiten seguir cómo estos son compartidos a través de la plataforma y crear perfiles de sus usuarios.
La web social no está solo constituida por las redes sociales, sino también por todas aquellas plataformas que nos permiten crear y compartir información. Entre estas, los sistemas de publicación como los blogs, los sistemas de recomendación como Ding o Reddit y los dispositivos de búsqueda. Todas estas plataformas están dirigidas por algoritmos que responden a distintas cuestiones. En el caso del buscador Google, en un medio que consta de más de sesenta trillones de páginas y en el que se realizan más de dos millones de búsquedas por minuto, este servicio parte de la premisa «tú quieres la respuesta, no trillones de páginas web». A este fin, la indexación basada en palabras clave se hace insuficiente, por lo que PageRank imita la conducta del usuario para asignar un valor a las páginas y poder ofrecer los resultados más pertinentes. Esto se lleva a cabo mediante el seguimiento de links efectuados a y desde cada página. Al mismo tiempo, este algoritmo es asistido por otros que tienen en cuenta nuestro historial de búsquedas, analizan nuestro lenguaje y determinan nuestra localización para personalizar los resultados.
También son algoritmos los que computan datos extraídos de nuestras acciones para sugerirnos qué libros comprar en Amazon, qué vídeos ver en Youtube o qué anuncios mostrarnos en todas estas plataformas. A estos algoritmos con los que interactuamos cotidianamente podemos sumar otros, como Eigenstaste, desarrollado en Berkeley, un sistema de filtrado colaborativo, para la computación rápida de recomendaciones; el recientemente desarrollado en la Universidad Cornell y la Carnegie, que permite construir nuestra biografía a través de nuestras publicaciones en Twitter, o el desarrollado en el Imperial College London para identificar las cuentas de Twitter que corresponden a boots, permitiendo reducir el spam. La algoritmia tiene una cada vez mayor presencia en nuestra cultura, como muestran las entradas de #algopop, un tumblr dedicado a seguir las apariciones de algoritmos en la cultura popular y la vida cotidiana.
Estos ejemplos muestran cómo el acceso y la indexación de la información contenida en Internet se procesan automáticamente, a partir de datos extraídos de nuestro comportamiento en línea. Nuestras acciones crean un flujo de mensajes que modifican la masa inextricable de relaciones entre datos, modificando sutilmente la memoria común. Esto da lugar a que la comunicación en el «medio algorítmico» sea estigmérgica, es decir, en este las personas se comunican entre ellas modificando su medio común. Cada link que creamos y compartimos, cada tag que añadimos a una información, cada acto de aprobación, búsqueda, compra o retweet, es registrado en una estructura de datos, y posteriormente procesado para orientar e informar a otros usuarios. De este modo, los algoritmos nos asisten en nuestra navegación a través del inmenso cúmulo de informaciones de la red, tratando la información producida individualmente, para que pueda ser consumida por la colectividad. Pero, al gestionar la información, estos también reconstruyen relaciones y organizaciones, forman gustos y encuentros, pasando a configurar nuestro entorno e identidades. Las plataformas se constituyen en entornos socio-técnicos automatizados.

Máquina analítica de Babbage mostrada en el Museo King George III, 1844. Fuente: Wikimedia Commons.
La aplicación de la automatización a nuestra cultura tiene consecuencias epistemológicas, políticas y sociales a tener en cuenta. Entre ellas, el registro constante de nuestras acciones supone un cambio respecto a lo que es la privacidad, y el hecho de que estos algoritmos nos enrolan en procesos de los que no somos conscientes. Finalmente, a pesar de que nos dan acceso a información que, por su dimensión, ha dejado de ser humanamente discernible, ampliando nuestra agencia y capacidad de elección, lejos de ser neutros, estos algoritmos también albergan capacidades de control.
La mayoría de usuarios percibe la web como un medio de difusión, en el sentido de los medios tradicionales, sin ser conscientes de cómo la información es filtrada y procesada por el medio. Los algoritmos no solo son imperceptibles en su acción, y desconocidos, en muchos casos, por estar en manos de agencias comerciales y protegidos por las leyes de propiedad, sino que también se han hecho inescrutables. Ello es debido a la interrelación existente entre complejos sistemas de software y su constante actualización.
Por otro lado, estos no solo se aplican al análisis de datos, sino que, en un segundo momento, toman parte en el proceso de decisiones. Esto nos plantea si es lícito aceptar las decisiones tomadas de modo automático por algoritmos de los que no sabemos cómo operan y que no pueden estar sujetos a discusión pública. ¿Cómo podemos discutir la neutralidad de unos procesos que son independientes de los datos a los que se aplican? Finalmente, los algoritmos, al analizar datos registrados de nuestras acciones anteriores, tienen una fuerte dependencia del pasado, lo que podría derivar en el mantenimiento de estructuras y una escasa movilidad social, dificultando las conexiones fuera de clusters definidos de intereses y contactos.
Teniendo en cuenta que arbitran cómo fluye la información por la esfera pública, se hace necesario plantear metáforas que hagan aprehensibles estos procesos, más allá de los expertos en computación. Del mismo modo, hay que extender su comprensión y uso a la población para que pueda participar en la discusión acerca de qué problemas son susceptibles de una solución algorítmica y cómo plantearlos. Hay que fomentar la participación para mantener la diversidad ecológica de este medio y su relación con la pragmática.
Respecto a estas cuestiones, Mathew Fuller, uno de los iniciadores de los estudios sobre software (software studies), hace notar que, aunque los algoritmos constituyen la estructura interna del medio donde hoy en día se realiza la mayor parte del trabajo intelectual, escasamente son abordados desde un punto de vista crítico y humanístico, quedando relegados a su estudio técnico. En su obra Behind the Blip: Essays on the Culture of Software, este autor propone algunos métodos encaminados a esta crítica. Entre ellos, la ejecución de sistemas de información que pongan al descubierto su funcionamiento, estructura y condiciones de verdad; el mantenimiento de la poética de la conexión inherente al software social, o la promoción de un uso que siempre sobrepase las capacidades técnicas del sistema. Y la promoción de conexiones improbables que enriquezcan nuestro medio con nuevas posibilidades y perspectivas más amplias, dejando lugar a la invención.
En este sentido, podemos citar algunas iniciativas en torno al «medio algorítmico» que ya se llevan a cabo y que contribuyen al uso de la computación por no expertos, y a la elaboración de este medio por comunidades de prácticas y usuarios. Entre estas, el periodismo de datos, que elabora narrativas a partir del minado de datos; el software libre, que desarrolla sus productos en colaboración con sus usuarios; las iniciativas de crowdsourcing, que añaden a la ecología de la red datos obtenidos por los usuarios de modo consciente y colaborativo, y la creciente elaboración colaborativa de MOOC (cursos masivos en línea).
Por su parte, también se hace necesaria la presencia de las instituciones culturales en el medio virtual. La accesibilidad en línea a sus archivos, datos, modos de hacer y saberes, proyectos y colaboradores contribuye a promover nuevos intereses y relaciones, aprovechando la estigmergia para mantener la diversidad y la poética de este medio. Al mismo tiempo, la proposición de workshops, como los programados en Universo Internet, contribuye a la comprensión y consciencia de este medio, para una mayor y más efectiva participación.
En este momento, el medio algorítmico incrementa su capacidad y alcance, debido a la aplicación de la inteligencia artificial. Es el caso del nuevo algoritmo semántico de Google, Hummingbird –capaz de analizar el lenguaje natural– o del nuevo reto planteado por Mark Zukenberg «entender el mundo», gracias al análisis del contenido de los post compartidos en Facebook. La discusión crítica y pública de la participación de estos dispositivos en la conformación de nuestra cultura es una necesidad si queremos mantener la diversidad y accesibilidad de la red




{kind=link}
adolflow | 03 marzo 2014
Interesantísimo, gran resumen.
Un detalle, la imagen de NotaG ya no está disponible:
http://commons.wikimedia.org/wiki/File:Representaci%C3%B3n_de_un_programa_de_ordenador_para_la_m%C3%A1quina_anal%C3%ADtica.png
Equip CCCB LAB | 03 marzo 2014
Gracias. Ya hemos quitado la imagen de «Nota G»
Oriol Abad Hogeland | 13 marzo 2014
Un control és un negoci.
Deja un comentario