
Feria de la eficiencia en el Amsterdam RAI, 1987 | Nationaal Archief | Dominio público
La producción masiva de datos ha propiciado un nuevo despertar de la inteligencia artificial, en el que los algoritmos son capaces de aprender de nosotros y devenir agentes activos en la producción de nuestra cultura. Procedimientos basados en el funcionamiento de nuestras capacidades cognitivas han dado lugar a algoritmos capaces de analizar los textos e imágenes que compartimos para predecir nuestra conducta. En este escenario, surgen nuevos retos sociales y éticos sobre la convivencia y el control de estos algoritmos, que lejos de ser neutrales, también aprenden y reproducen nuestros prejuicios.
Eva quiere ser libre, salir al exterior y conectar con el mundo cambiante y complejo de los humanos. La protagonista de Ex Machina es el resultado del modelado de nuestro pensamiento a partir de la base de datos recopilada por el motor de búsqueda Blue book, un ser inteligente y capaz de actuar de modo imprevisto, que, viendo su supervivencia amenazada, conseguirá burlar a su examinador y acabar con su creador. Tradicionalmente la ciencia ficción nos ha acercado al fenómeno de la inteligencia artificial recurriendo a encarnaciones humanoides, seres superhumanos que cambiarían el curso de nuestra evolución. Aunque aún estamos lejos de conseguir una inteligencia artificial fuerte, un cambio de paradigma en este campo de estudio está produciendo aplicaciones que afectan cada vez a más facetas de nuestra vida cotidiana y modifican nuestro entorno, a la vez que plantean nuevos retos éticos y sociales.
A medida que nuestra vida cotidiana se halla cada vez más mediatizada por la red y se incrementa el aluvión de datos que alimenta este sistema, los algoritmos que rigen este medio se hacen más inteligentes. El aprendizaje automático (machine learning) produce aplicaciones especializadas que evolucionan gracias a los datos generados en nuestras interacciones con la red y que están penetrando y modificando nuestro entorno de modo sutil e inadvertido. La inteligencia artificial está evolucionando hacia un medio tan ubicuo como la electricidad, ha penetrado en las redes sociales convirtiéndose en un agente autónomo capaz de modificar nuestra inteligencia colectiva y, a medida que este medio se incorpora al espacio físico, está modificando el modo en que percibimos y actuamos en el mismo. A medida que este nuevo entramado tecnológico se aplica a más campos de actividad, queda por ver si esta es una inteligencia artificial para el bien, capaz de comunicarse de un modo eficiente con el ser humano y aumentar nuestras capacidades o un mecanismo de control que, al mismo tiempo que nos sustituye en tareas especializadas, captura nuestra atención convirtiéndonos en consumidores pasivos.
Algoritmos inteligentes en la red
A principios de año, Mark Zuckerberg publicó la nota Construyendo una Comunidad Global dirigida a todos los usuarios de la red social Facebook. En este texto, Zuckerberg aceptaba la responsabilidad social de este medio, a la vez que lo definía como un agente activo en la comunidad global y comprometido en colaborar en la gestión de emergencias, el control del terrorismo y la prevención del suicidio. Estas promesas radican en un cambio en los algoritmos que rigen esta plataforma. Si hasta ahora la red social filtraba la gran cantidad de información subida a la plataforma recopilando datos de las reacciones y contactos de sus usuarios, ahora el desarrollo de algoritmos inteligentes permite comprender e interpretar el contenido de estas informaciones. De este modo, Facebook ha desarrollado la herramienta Deep Text, que aplica aprendizaje automático para comprender lo que los usuarios dicen en sus posts, y crear modelos de clasificación de intereses generales. La inteligencia artificial también es empleada para la identificación de imágenes. DeepFace es una herramienta que permite identificar los rostros en fotografías con un nivel de acierto cercano al de los seres humanos. La visión computerizada también se aplica a generar descripciones textuales de las imágenes en el servicio Automatic Alternative text dirigido a que los invidentes puedan saber qué están publicando sus contactos. Asimismo, ha permitido al Connectivity Lab de esta compañía generar el mapa de población más exacto hasta la fecha. En su esfuerzo por administrar conexión a la red a todo el mundo mediante drones, este laboratorio ha analizado imágenes por satélite de todo el globo en busca de edificaciones que revelaran presencia humana. Estos datos, en combinación con las bases de datos demográficas existentes, ofrecen información exacta de donde se localizan los potenciales usuarios de la conectividad ofrecida por los drones.
Estas aplicaciones y muchas otras, que testea y aplica periódicamente la compañía, se basan en el FBLearner Flow, la estructura que facilita la aplicación y el desarrollo de inteligencia artificial a toda la plataforma. Flow es un motor automatizado de aprendizaje automático que permite entrenar hasta trescientos mil modelos cada mes, asistido por AutoML, otra aplicación inteligente que limpia los datos para ser empleados en redes neuronales. Estas herramientas automatizan la producción de algoritmos inteligentes, que son aplicados a jerarquizar y personalizar el muro de los usuarios, filtrar contenidos ofensivos, resaltar tendencias, ordenar resultados de búsquedas y muchas otras cosas que están cambiando nuestra experiencia en la plataforma. La novedad de estas herramientas es que no solo modelan el medio conforme a nuestras acciones, sino que, al acceder a la interpretación de los contenidos que publicamos, permite a la compañía extraer patrones de nuestra conducta, prever nuestras reacciones e influenciarlas. En el caso de las herramientas puestas a disposición para la prevención del suicidio, actualmente consta de un menú desplegable que permite reportar posibles casos y acceder a información útil como números de contacto y vocabulario para dirigirse a la persona en riesgo de modo adecuado. Sin embargo, estos casos reportados forman una base de datos que, analizada, da lugar a patrones de conducta identificables que en un futuro cercano permitirían a la plataforma prever una posible incidencia y reaccionar de modo automatizado.
Por su parte, Google es la compañía detrás del último gran logro de la inteligencia artificial. Alpha Go está considerado el primer programa de inteligencia general. El programa, desarrollado por Deep Mind, la compañía de inteligencia artificial adquirida por Google en 2014, no solo emplea aprendizaje automático que le permite aprender analizando un registro de jugadas, sino que además integra aprendizaje reforzado que le permite elaborar estrategias aprendidas jugando contra sí mismo y en otros juegos. El año pasado este programa ganó a Lee Sedol, el mayor maestro de Go, un juego considerado como el más complejo creado por la inteligencia humana. Este hecho no solo ha contribuido al bombo publicitario que rodea la inteligencia artificial, sino que ha colocado a esta compañía a la cabeza de este nuevo entramado tecnológico. Google ha liderado los cambios que han marcado la evolución de los buscadores web, y ahora plantea un mundo de inteligencia artificial (AI first world) que cambiaría el paradigma que rige nuestra relación con este medio. Este cambio fue introducido en la carta dirigida a los inversores de este año, cuya redacción Larry Page y Sergey Brin han cedido a Sundar Pichai, el CEO de Google, quien ha introducido el asistente Google.
Google aplica el aprendizaje automático a su buscador para autocompletar y corregir los términos de búsqueda que introducimos. Para este fin utiliza el procesado de lenguaje natural, tecnología que también le ha permitido desarrollar su traductor y el reconocimiento de voz y crear Allo, una interfaz conversacional. Por otro lado, la visión computerizada ha dado lugar al servicio de búsqueda por imágenes, y es lo que permite a la nueva aplicación Google Photos clasificar nuestras imágenes sin necesidad de etiquetarlas previamente. Otras aplicaciones de inteligencia artificial permiten a Perspective analizar y denunciar comentarios tóxicos para reducir el acoso y abuso en la web, e incluso reducir el coste energético de sus granjas de servidores de datos.
El asistente de Google supondría un nuevo modo de obtener información en la plataforma que sustituiría la página de resultados de búsqueda por una interfaz conversacional. En esta un agente inteligente accedería a todos estos servicios para comprender nuestro contexto, situación y necesidades y elaborar, ya no una lista de opciones, sino una acción como respuesta a nuestras preguntas. De este modo, Google ya no proporcionaría acceso a información sobre un espectáculo, los horarios y lugar de emisión y venta de entradas, sino un servicio integrado que compraría las entradas y programaría el espectáculo en nuestra agenda. Este asistente podría organizar nuestra agenda, administrar nuestros pagos y presupuestos y muchas otras cosas que contribuirían a convertir nuestros móviles en los controles remotos de nuestras vidas.
El aprendizaje automático se sustenta en el análisis de datos produciendo sistemas autónomos que evolucionan con el uso. Estos sistemas generan su propio ecosistema de innovación en un rápido avance que está conquistando todo el medio de Internet. Los algoritmos inteligentes rigen el sistema de recomendación de Spotify; es lo que permite a la aplicación Shazam escuchar y reconocer canciones y está detrás del éxito de Netflix, que no solo los utiliza para recomendar y distribuir sus productos, sino también para planear su producción y ofrecer series y películas al gusto de sus usuarios. A medida que se incrementa el número de dispositivos conectados que generan datos, la inteligencia artificial se infiltra en todas partes. Amazon no solo la emplea en sus algoritmos de recomendación, sino asimismo en la gestión de su logística y en la creación de vehículos autónomos que puedan trasportar y entregar sus productos y la aplicación para compartir transporte Uber los emplea para perfilar la reputación de sus conductores y usuarios, para emparejarlos, proponer las rutas y calcular los precios dentro de su sistema variable. Estas interacciones producen una base de datos que la compañía está empleando en la producción de su vehículo autónomo.
Los vehículos autónomos son otro de los hitos de la inteligencia artificial. Desde que el GPS se implantó en los vehículos en 2001, se ha producido una gran base de datos de navegación que, junto con el desarrollo de nuevos sensores, ha hecho posible a Google crear un vehículo autónomo que ya ha recorrido cerca de 500.000 km sin ningún accidente y que ha anunciado su comercialización con el nombre de Waymo.
La inteligencia artificial también se implementa en asistentes para nuestros hogares, como el Google Home y el Echo de Amazon y en dispositivos wearables que recolectan datos sobre nuestras constantes vitales y que, junto con la digitalización de las imágenes diagnósticas y los expedientes médicos, está dando lugar a la aplicación de algoritmos de predicción y robots destinados a la salud. Asimismo, la multiplicación de cámaras de vigilancia y registros policiales está conduciendo a la aplicación de algoritmos inteligentes para la predicción del crimen y la toma de decisiones judiciales.
Aprendizaje automático, el nuevo paradigma de la inteligencia artificial
El medio algorítmico en que tenían lugar nuestras interacciones sociales se ha hecho inteligente y autónomo, aumentando su capacidad de predicción y control de nuestra conducta, al mismo tiempo que ha migrado de las redes sociales para extenderse a todo nuestro entorno. El nuevo auge de la inteligencia artificial se debe a un cambio de paradigma que ha llevado a este entramado tecnológico de la definición lógica de los procesos intelectuales a un enfoque pragmático sustentado en datos y que permite a los algoritmos aprender del entorno.
Nils J.Nilson define la inteligencia artificial como una actividad dedicada a hacer a las máquinas inteligentes, y la inteligencia como la cualidad que permite a una entidad funcionar de manera apropiada y con conocimiento de su entorno. El término inteligencia artificial fue usado por primera vez por John McCarthy en la propuesta escrita junto con Marvin Minsky, Nathaniel Rochester y Claude Shanon para el workshop de Dartmouth de 1956. Este evento fundacional estaba destinado a convocar a un grupo de especialistas que investigaran modos en que las máquinas simularan aspectos de la inteligencia humana. Este estudio se basa en la conjetura de que cualquier aspecto del aprendizaje o cualquier otra característica de la inteligencia pueden describirse de forma suficientemente precisa para ser simulada por una máquina. La misma conjetura que llevó a Alain Turing a proponer el modelo formal de la computadora en su artículo de 1950 Computer machinery and Intelligence. Junto con otros precedentes, como la lógica booleana, la probabilidad bayesiana y el desarrollo de la estadística, se llevaron a cabo progresos en lo que Minsky definió como el avance en la inteligencia artificial: el desarrollo de computadores y la mecanización de la solución de problemas.
Sin embargo, a mediados de los años ochenta, seguía habiendo un desfase respecto al desarrollo teórico de la disciplina y su aplicación práctica, que provocó la retirada de fondos y un estancamiento conocido como el «invierno de la inteligencia artificial». Esta situación cambió con la difusión de Internet y su gran capacidad para recabar datos. Los datos han permitido conectar la solución de problemas a la realidad en un enfoque más pragmático e inspirado en la biología. En este, en lugar de haber un programador que escribe las órdenes que llevarían a la solución de un problema, el programa genera su propio algoritmo basado en datos de ejemplo y el resultado deseado. En el aprendizaje automático, la máquina se programa ella misma. Este paradigma se ha impuesto gracias al gran éxito empírico de las redes neuronales artificiales que pueden ser entrenadas con datos masivos y con computación a gran escala. Este procedimiento se conoce como aprendizaje profundo (deep learning) y consiste en capas de redes neuronales interconectadas que imitan de forma laxa el comportamiento de las neuronas biológicas, sustituyendo las neuronas por nodos y las conexiones sinápticas por conexiones entre estos nodos. En vez de analizar un conjunto de datos como un todo, este sistema lo descompone en sus partes mínimas y recuerda las conexiones entre estas partes formando patrones que son transmitidos de una capa a la siguiente, incrementando su complejidad hasta conseguir el resultado deseado. De este modo, en el caso del reconocimiento de imágenes, la primera capa calcularía las relaciones de intensidad entre los píxeles de la imagen y transmitiría la señal a la siguiente capa y así sucesivamente hasta producir un output completo, la identificación del contenido de la imagen. Estas redes pueden ser entrenadas gracias a la propagación inversa (back propagation), una propiedad que permite cambiar las relaciones calculadas conforme a una corrección humana hasta conseguir el resultado deseado. De este modo, el gran poder de la actual inteligencia artificial es que no se detiene en la definición de entidades, sino que descifra la estructura de relaciones que dan forma y textura a nuestro mundo. Un proceso similar es aplicado a la comprensión del lenguaje natural (natural language processing): este procedimiento observa las relaciones entre palabras para inferir el significado de un texto sin necesidad de definiciones previas. Otros campos de estudio contenidos en el actual desarrollo de la inteligencia artificial constituyen el aprendizaje reforzado (reinforced learning), un procedimiento que cambia el enfoque del aprendizaje automático del reconocimiento de patrones en la toma de decisiones guiadas por la experiencia. El crowdsourcing y la colaboración entre humanos y máquinas también se consideran parte de la inteligencia artificial y han dado lugar a servicios como el Mechanical Turk de Amazon, un servicio en que seres humanos etiquetan imágenes o textos para ser usados en el entrenamiento de redes neuronales.
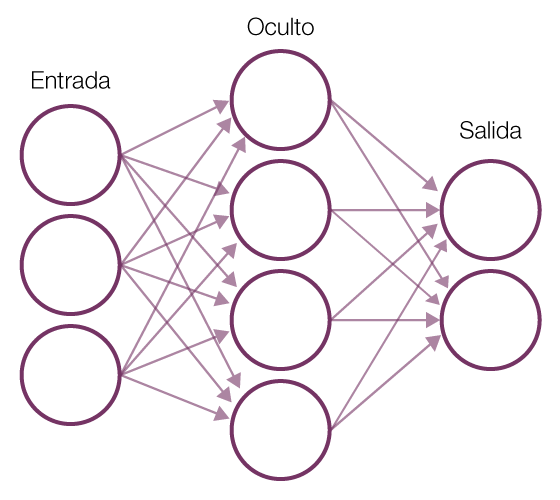
Red neuronal artificial | Wikipedia
La fragilidad del sistema: la cooperación entre humanos y algoritmos inteligentes
La inteligencia artificial promete mayor personalización y una relación más fácil e integrada con las máquinas. Aplicada a campos como el transporte, la salud, la educación o la seguridad, se emplea para vigilar nuestro bienestar, alertarnos de posibles riesgos y ofrecer servicios cuando sean solicitados. Sin embargo, la implantación de estos algoritmos ha dado lugar a algunos eventos escandalosos que han alertado sobre la fragilidad de este sistema. Entre ellos el aparatoso accidente del vehículo semiautomático de Tesla, la difusión de noticias falsas en redes como Facebook y Twitter, el fallido experimento del bot Tai desarrollado por Microsoft y liberado a la plataforma Twitter para aprender en interacción con los usuarios (este tuvo que ser retirado en menos de 24 horas debido a sus comentarios ofensivos). El etiquetado de personas afroamericanas en Google Photos como «simios», la constatación de que Google es menos propenso a mostrar demandas de empleo de nivel alto a mujeres que a hombres o de que los delincuentes afroamericanos son con mayor frecuencia clasificados como potenciales reincidentes que los caucasianos han mostrado, entre otros problemas, el poder discriminatorio de estos algoritmos, su capacidad de comportamientos emergentes y la difícil cooperación con los humanos.
Estos y otros problemas se deben, por un lado, a la naturaleza del aprendizaje automático, su dependencia del big data, su gran complejidad y capacidad de previsión. Por otro lado, a su implementación social, donde encontramos problemas derivados de la concentración de estos procedimientos en unas pocas compañías (Apple, Facebook, Google, IBM y Microsoft), la dificultad de garantizar un acceso igualitario a sus beneficios y la necesidad de crear estrategias de resiliencia frente a los cambios que se producen conforme estos algoritmos van penetrando en la estructura crítica de la sociedad.
La falta de neutralidad de los algoritmos se debe a la dependencia del big data. Las bases de datos no son neutrales y presentan los prejuicios inherentes al hardware con que han sido recolectados, el propósito para el que han sido recopilados y al paisaje desigual de datos ‒no existe la misma densidad de datos en todas las zonas urbanas ni respecto a todos los estamentos y hechos sociales. La aplicación de algoritmos entrenados con estos datos puede difundir los prejuicios presentes en nuestra cultura como un virus, dando lugar a círculos viciosos y a la marginalización de sectores de la sociedad. El tratamiento de este problema pasa por la elaboración de bases de datos inclusivas y un cambio de enfoque en la orientación de estos algoritmos hacia el cambio social.
El crowdsourcing puede favorecer la creación de bases de datos más justas, colaborar a valorar qué datos son sensibles en cada situación y proceder a su eliminación y a testear la neutralidad de las aplicaciones. En este sentido, un equipo de las universidades de Columbia, Cornell y Saarland ha elaborado la herramienta FairTest, que busca asociaciones injustas que pueden producirse en un programa. Por otra parte, orientar los algoritmos hacia el cambio social puede contribuir a la detección y eliminación de los prejuicios presentes en nuestra cultura. La Universidad de Boston, en colaboración con el Microsoft Research, ha llevado a cabo un proyecto en que los algoritmos son utilizados para la detección de los prejuicios recogidos en la lengua inglesa, concretamente las asociaciones injustas que se dan en la base de datos Word2vec, usada en muchas aplicaciones de clasificación automática de texto, traducción y buscadores. El hecho de eliminar los prejuicios de esta base de datos no los elimina de la cultura, pero evita su propagación por medio de aplicaciones que funcionan de modo recurrente.
Otros problemas se deben a la falta de transparencia, que deriva no solo del hecho de que estos algoritmos son considerados y protegidos como propiedad de las compañías que los implementan, sino de su complejidad. Sin embargo, el desarrollo de procesos que haga estos algoritmos explicativos es de esencial importancia cuando estos se aplican a la toma de decisiones médicas, judiciales o militares, donde pueden vulnerar el derecho que tenemos a recibir una explicación satisfactoria respecto a una decisión que afecta a nuestra vida. En este sentido, la Agencia de Investigación para la Defensa Americana (DARPA) ha iniciado el programa Inteligencia artificial explicativa (Explainable Artificial Intelligence). Este explora nuevos sistemas de conocimiento profundo que puedan incorporar una explicación de su razonamiento, resaltando las áreas de una imagen consideradas relevantes para su clasificación o revelando un ejemplo de la base de datos que muestre el resultado. También desarrollan interfaces que hagan el proceso del aprendizaje profundo con los datos más explícitos, mediante visualizaciones y explicaciones en lenguaje natural. Un ejemplo de estos procedimientos lo encontramos en uno de los experimentos de Google. Deep Dream, llevado a cabo en 2015, consistió en modificar un sistema de reconocimiento de imágenes basado en aprendizaje profundo para que, en lugar de identificar objetos contenidos en las fotografías, los modificara. Este proceso inverso permite, además de crear imágenes oníricas, visualizar las características que el programa selecciona para identificar las imágenes, mediante un proceso de deconstrucción que fuerza al programa a trabajar fuera de su marco funcional y desvelar su funcionamiento interno.
Por último, la capacidad de previsión de estos sistemas los lleva a un incremento en la capacidad de control. Son conocidos los problemas de privacidad que se derivan del uso de tecnologías en red, pero la inteligencia artificial puede analizar nuestras decisiones anteriores y prever nuestras posibles actividades futuras; esto da al sistema capacidad para influenciar en la conducta de los usuarios, lo cual reclama un uso responsable y el control social de su aplicación.
Ex Machina nos ofrece una metáfora del temor que rodea la inteligencia artificial, que esta supere nuestras capacidades y escape a nuestro control. La probabilidad de que la inteligencia artificial produzca una singularidad o un evento que cambiaría el curso de nuestra evolución humana sigue siendo remota; sin embargo, los algoritmos inteligentes del aprendizaje automático se están diseminando en nuestro entorno y produciendo cambios sociales significativos, por lo que es necesario desarrollar estrategias que permitan a todos los agentes sociales comprender los procesos que estos algoritmos generan y participar en su definición e implementación.






{kind=link}
Deja un comentario