
Retrat d’Ada Lovelace, primera programadora de la història dels computadors. Autor: William Henry Mote, 1838. Font: The Ada Picture Gallery.
L’ús d’Internet s’ha estès, més enllà dels ordinadors i de qualsevol àmbit específic, i s’ha infiltrat en la textura de la nostra realitat i en tots els aspectes de la nostra vida quotidiana. La manera en què ens relacionem, ens informem, prenem decisions… en definitiva, coneixem i experimentem el nostre entorn, està cada vegada més mediatitzada pels sistemes d’informació que conformen aquesta xarxa. Aquesta interacció constant dóna lloc a una producció massiva d’informació que només pot ser gestionada de manera automatitzada, per mitjà de l’aplicació d’algoritmes. Entendre com s’ha format i com interactuem amb aquest «mitjà algorítmic», des d’un enfocament humanístic, és indispensable perquè tant els ciutadans com les institucions mantinguin un paper actiu en la conformació de la nostra cultura.
Un jove magnat de la informació i les finances travessa Manhattan en una limusina. Així comença Cosmopolis, l’última pel·lícula de David Cronenberg, basada en l’obra de Don DeLillo. Durant el trajecte, Eric Packer analitza el flux d’informacions que li proporcionen unes pantalles, mentre ens porta a la cerca d’una nova perspectiva. La trobada amb diferents personatges, com també la irrupció de la ciutat i els seus sorolls a través de les finestretes, ens deixen veure els detalls, les conseqüències i els intersticis del que en el film s’anomena cibercapitalisme. El viatge acaba amb l’enfrontament del protagonista –arruïnat a causa d’un comportament erràtic del mercat que els bells números dels seus algoritmes no poden preveure– amb el seu personatge antitètic, algú que no troba el seu lloc en el sistema.
La interacció de tecnologia i capital, és a dir, el processament automàtic de dades massives per a la previsió i el control de les fluctuacions del mercat, és una constant de l’especulació capitalista. En efecte, a Wall Street un 65% de les operacions les duen a terme programes d’«algo trading». En un mercat global, on es registren grans masses de dades i on una resposta ràpida suposa un avantatge sobre la competència, els algoritmes tenen un paper cabdal tant en l’anàlisi com en la presa de decisions.
Ara bé, els algoritmes s’han anat infiltrant en tots els processos que conformen la nostra cultura i vida quotidiana. Conformen el software que fem servir per produir objectes culturals, programes que tot sovint s’ofereixen de manera lliure al núvol. De la mateixa manera, operen en la distribució d’aquests objectes a través de la xarxa i en la cerca i recuperació d’aquests per part dels usuaris. Finalment, s’han fet necessaris per a l’anàlisi i el processament de les dades massives que produeix el web social. Dades no sols referides al sempre creixent nombre d’aportacions, sinó també obtingudes del seguiment de les accions dels usuaris, en un web que s’ofereix com a plataforma per a la participació i que creix i evoluciona amb l’ús.
Un algoritme és una llista finita d’instruccions que s’apliquen a un input durant un nombre finit d’estats per obtenir un output, cosa que permet fer càlculs i processar dades de manera automàtica.
L’expressió algoritme prové del nom del matemàtic persa del segle IX al-Khal-Khwarizm i al principi feia referència al conjunt de regles per desenvolupar operacions aritmètiques amb nombres àrabs. Aquest terme va anar evolucionant fins a definir un conjunt de regles per executar una funció. La relació d’aquesta expressió amb l’automatització es deu a Babbage i la seva hipòtesi segons la qual el total d’operacions involucrat en el desenvolupament d’una anàlisi podia ser executat per màquines. Per això, tot procés s’havia de dividir en operacions simples i independents de la realitat a processar. Malgrat el desenvolupament de la seva màquina diferencial i la proposta per part d’Ada Lovelace del primer algoritme per ser desenvolupat en una màquina, va ser Alan Turing qui, el 1937, va proposar la formalització definitiva de l’algoritme amb la seva màquina universal. El constructe teòric de Turing consta d’un aparell hipotètic que manipula signes en una cinta d’acord amb una taula de regles definides, i pot ser aplicat a l’anàlisi de la lògica interna de qualsevol ordinador. L’adveniment d’Internet suposarà la sortida d’aquest esquema lògic de l’ordinador. El protocol Internet (1969) i la invenció del web (1995) van permetre un contenidor universal, on les dades podien ser emmagatzemades, accedides i processades des de qualsevol ordinador. Tot plegat, juntament amb la convergència vinculada al desenvolupament als anys vuitanta, duria a estendre la computació, el càlcul numèric, a qualsevol procés digitalitzat. Alhora, els algoritmes, gràcies a les URL, podien interactuar i connectar-se entre ells. Això donarà lloc al que Pierre Lévy anomena «mitjà algorítmic». Una estructura cada vegada més complexa de manipulació automàtica de símbols que passarà a constituir el mitjà on les xarxes humanes construeixen i modifiquen, de manera col·laborativa, la seva memòria comuna.
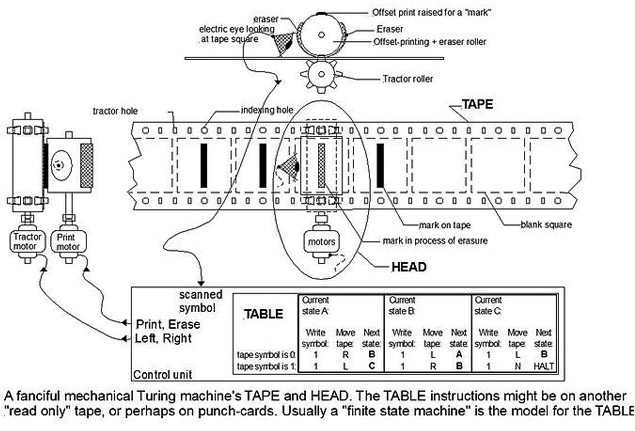
Màquina de Turing. Font: Wikimedia Commons.
Els algoritmes operen en totes les nostres interaccions quotidianes amb el web social. La coneguda xarxa social Facebook, a la qual es connecten 699 milions d’usuaris cada dia, es planteja el problema de com mostrar les actualitzacions dels múltiples amics, grups i interessos que la xarxa permet seguir. La solució a aquesta qüestió és Edgerank. Aquest algoritme analitza les dades recollides sobre els nostres interessos –els «m’agrada» que premem–, el nombre d’amics que tenim en comú amb l’emissor de la història, com també els comentaris fets, per determinar quin post mostrar en el nostre «news feed» i ocultar les històries «avorrides». De la mateixa manera, és un algoritme el que rastreja el graf dels nostres contactes per suggerir-nos nous amics.
Twitter actua de manera similar quan ens suggereix nous comptes per seguir, elaborar el contingut de la pestanya «descobreix» o la llista dels «trend topics». En aquest últim cas, hi treballa un complex algoritme que no es limita a comptabilitzar la paraula més twittejada, sinó que té en compte si un terme s’ha accelerat en el seu ús, si ha estat tendència anteriorment, o si aquest es fa servir en diverses xarxes o només dins d’un clúster densament connectat d’usuaris. Amb aquesta finalitat, l’algoritme no sols compta amb el seguiments dels «hastags», l’etiqueta que permet linkar amb totes les històries que la contenen –proposada el 2007 per aquesta plataforma i que ha estès el seu ús a tot el web social–, sinó que compta també amb la tecnologia dels links abreujats. Els t.co (f.bo, en el cas del Facebook) es generen cada vegada que compartim un web a través d’un botó social. Aquests permeten no sols economitzar el nombre de caràcters, sinó que converteixen els links en estructures riques en dades, que permeten seguir com aquestes són compartides a través de la plataforma i crear perfils dels seus usuaris.
El web social no està només constituït per les xarxes socials, sinó també per totes aquelles plataformes que ens permeten crear i compartir informació. Entre aquestes, els sistemes de publicació com els blogs, els sistemes de recomanació com Ding o Reddit i els dispositius de recerca. Totes aquestes plataformes estan dirigides per algoritmes que responen a diferents qüestions. En el cas del cercador Google, en un mitjà que consta de més de seixanta trilions de pàgines i en què es fan més de dos milions de cerques per minut, aquest serveix parteix de la premissa «tu vols la resposta, no trilions de pàgines web». Amb aquest objectiu, la indexació basada en paraules clau esdevé insuficient, per la qual cosa PageRank imita la conducta de l’usuari per assignar un valor a les pàgines i poder oferir els resultats més pertinents. Això es duu a terme per mitjà del seguiment de links efectuats a i des de cada pàgina. Al mateix temps, aquest algoritme és assistit per d’altres que tenen en compte el nostre historial de cerques, analitzen el nostre llenguatge i determinen la nostra localització per personalitzar els resultats.
També són algoritmes els que computen dades extretes de les nostres accions per suggerir-nos quins llibres comprar a Amazon, quins vídeos veure a Youtube o quins anuncis mostrar-nos en totes aquestes plataformes. A aquests algoritmes amb què interactuem cada dia, en podem afegir d’altres, com Eigenstaste, desenvolupat a Berkeley, un sistema de filtratge col·laboratiu, per a la computació ràpida de recomanacions; el recentment desenvolupat a la Universitat Cornell i la Carnegie, que permet construir la nostra biografia a través de les nostres publicacions a Twitter, o el desenvolupat a l’Imperial College London per identificar els comptes de Twitter que corresponen a boots, cosa que permet reduir l’spam. L’algorítmia cada vegada té més presència a la nostra cultura, com mostren les entrades d’#algopop, un tumblr dedicat a seguir les aparicions d’algoritmes en la cultura popular i la vida quotidiana.
Aquests exemples mostren com l’accés i la indexació de la informació continguda a Internet es processen automàticament, a partir de dades extretes del nostre comportament en línia. Les nostres accions creen un flux de missatges que modifiquen la massa inextricable de relacions entre dades, cosa que modifica de manera subtil la memòria comuna. Això dóna lloc a què la comunicació en el «mitjà algorítmic» sigui estigmèrgica, és a dir, les persones s’hi comuniquen modificant el seu mitjà comú. Cada link que creem i compartim, cada tag que afegim a una informació, cada acte d’aprovació, cerca, compra o retweet, és registrat en una estructura de dades, i posteriorment processat per orientar i informar altres usuaris. D’aquesta manera, els algoritmes ens assisteixen en la nostra navegació a través de l’immens cúmul d’informacions de la xarxa, tractant la informació produïda individualment, a fi que pugui ser consumida per la col·lectivitat. Però, en gestionar la informació, aquests també reconstrueixen relacions i organitzacions, formen gustos i trobades, amb la qual cosa passen a configurar el nostre entorn i les nostres identitats. Les plataformes es constitueixen en entorns sociotècnics automatitzats.

Màquina analítica de Babbage mostrada en el Museu King George III, 1844. Font: Wikimedia Commons.
L’aplicació de l’automatització a la nostra cultura té conseqüències epistemològiques, polítiques i socials que cal tenir en compte. Entre elles, el registre constant de les nostres accions suposa un canvi respecte al que és la privacitat, i el fet que aquests algoritmes ens enrolen en processos dels quals no som conscients. Finalment, malgrat que ens donen accés a informació que, per la seva dimensió, ha deixat de ser humanament discernible, ampliant la nostra agència i capacitat d’elecció, lluny de ser nostres, aquests algoritmes contenen capacitats de control.
La majoria d’usuaris percep el web com un mitjà de difusió, en el sentit dels mitjans tradicionals, sense ser conscients de com la informació és filtrada i processada pel mitjà. Els algoritmes no sols són imperceptibles en la seva acció, i desconeguts, en molts casos, per estar en mans d’agències comercials i protegits per les lleis de propietat, sinó que també s’han fet inescrutables. Això és degut a la interrelació que hi ha entre complexos sistemes de software i la seva actualització constant.
D’altra banda, aquests no sols s’apliquen a l’anàlisi de dades, sinó que, en un segon moment, prenen part en el procés de decisions. Això ens planteja si és lícit acceptar les decisions preses de manera automàtica per algoritmes dels quals no sabem com operen i que no poden estar subjectes a discussió pública. Com podem discutir la neutralitat d’uns processos que són independents de les dades a què s’apliquen? Finalment, els algoritmes, en analitzar dades registrades de les nostres accions anteriors, tenen una forta dependència del passat, cosa que podria derivar en el manteniment d’estructures i una escassa mobilitat social, dificultant les connexions fora de clústers definits d’interessos i contactes.
Tenint en compte que arbitren com flueix la informació per l’esfera pública, es fa necessari plantejar metàfores que facin entenedors aquests processos, més enllà dels experts en computació. De la mateixa manera, cal estendre’n la comprensió i l’ús a la població a fi que pugui participar en la discussió sobre quins problemes són susceptibles d’una solució algorítmica i com plantejar-los. Cal fomentar la participació per mantenir la diversitat ecològica d’aquest mitjà i la seva relació amb la pragmàtica.
Pel que fa a aquestes qüestions, Mathew Fuller, un dels iniciadors dels estudis sobre software (software studies), fa notar que, tot i que els algoritmes constitueixen l’estructura interna del mitjà on avui dia es duu a terme la major part del treball intel·lectual, s’aborden poc sovint des d’un punt de vista crític i humanístic, amb la qual cosa queden relegats al seu estudi tècnic. A la seva obra Behind the Blip: Essays on the Culture of Software, aquest autor proposa uns quants mètodes encaminats a aquesta crítica. Entre ells, l’execució de sistemes d’informació que en posin al descobert el funcionament, l’estructura i les condicions de debò; el manteniment de la poètica de la connexió inherent al software social, o la promoció d’un ús que sempre sobrepassi les capacitats tècniques del sistema. I la promoció de connexions improbables que enriqueixin el nostre mitjà amb noves possibilitats i perspectives més àmplies, deixant lloc a la invenció.
En aquest sentit, podem esmentar algunes iniciatives al voltant del «mitjà algorítmic» que ja es duen a terme i que contribueixen a l’ús de la computació per part de no experts, i a l’elaboració d’aquest mitjà per comunitats de pràctiques i usuaris. Entre aquestes, el periodisme de dades, que elabora narratives a partir del minat de dades; el software lliure, que desenvolupa els seus productes en col·laboració amb els seus usuaris; les iniciatives de crowdsourcing, que afegeixen a l’ecologia de la xarxa dades obtingudes pels usuaris de manera conscient i col·laborativa, i la creixent elaboració col·laborativa de MOOC (cursos massius en línia).
Per la seva banda, també es fa necessària la presència de les institucions culturals en el medi virtual. L’accessibilitat en línia als seus arxius, dades, maneres de fer i coneixements, projectes i col·laboradors contribueix a promoure nous interessos i relacions, aprofitant l’estigmèrgia per mantenir la diversitat i la poètica d’aquest mitjà. Al mateix temps, la proposició de workshops, com els programats a Univers Internet, contribueix a la comprensió i consciència d’aquest mitjà, per a una participació més gran i més efectiva.
En aquest moment, el mitjà algorítmic incrementa la seva capacitat i el seu abast, gràcies a l’aplicació de la intel·ligència artificial. És el cas del nou algoritme semàntic de Google, Hummingbird –capaç d’analitzar el llenguatge natural– o del nou repte plantejat per Mark Zukenberg «entendre el món», gràcies a l’anàlisi del contingut dels posts compartits al Facebook. La discussió crítica i pública de la participació d’aquests dispositius en la conformació de la nostra cultura és una necessitat si volem mantenir la diversitat i accessibilitat de la xarxa.




{kind=link}
adolflow | 03 març 2014
Interesantísimo, gran resumen.
Un detalle, la imagen de NotaG ya no está disponible:
http://commons.wikimedia.org/wiki/File:Representaci%C3%B3n_de_un_programa_de_ordenador_para_la_m%C3%A1quina_anal%C3%ADtica.png
Equip CCCB LAB | 03 març 2014
Gracias. Ya hemos quitado la imagen de “Nota G”
Oriol Abad Hogeland | 13 març 2014
Un control és un negoci.
Deixa un comentari