
Fira de l’eficiència a l’Amsterdam RAI, 1987 | Nationaal Archief | Domini públic
La producció massiva de dades ha afavorit un nou desvetllament de la intel·ligència artificial, en el qual els algoritmes són capaços d’aprendre de nosaltres i esdevenir agents actius en la producció de la nostra cultura. Procediments basats en el funcionament de les nostres capacitats cognitives han donat lloc a algoritmes capaços d’analitzar els textos i les imatges que compartim per predir la nostra conducta. En aquest escenari, sorgeixen nous reptes socials i ètics sobre la convivència i el control d’aquests algoritmes, que, lluny de ser neutrals, també aprenen i reprodueixen els nostres prejudicis.
L’Eva vol ser lliure, sortir a l’exterior i connectar amb el món canviant i complex dels humans. La protagonista d’Ex Machina és el resultat del modelatge del nostre pensament a partir de la base de dades recollida pel motor de cerca Blue book, un ésser intel·ligent i capaç d’actuar de manera imprevista, que, en veure la seva supervivència amenaçada, aconseguirà burlar el seu examinador i acabar amb el seu creador. Tradicionalment la ciència-ficció ens ha apropat al fenomen de la intel·ligència artificial recorrent a encarnacions humanoides, éssers superhumans que canviarien el curs de la nostra evolució. Tot i que encara estem lluny d’aconseguir una intel·ligència artificial forta, un canvi de paradigma en aquest camp d’estudi està produint aplicacions que afecten cada vegada més facetes de la nostra vida quotidiana i modifiquen el nostre entorn, alhora que plantegen nous reptes ètics i socials.
A mesura que la nostra vida quotidiana es troba cada vegada més mediatitzada per la xarxa i s’incrementa l’allau de dades que alimenta aquest sistema, els algoritmes que regeixen aquest mitjà es fan més intel·ligents. L’aprenentatge automàtic (machine learning) produeix aplicacions especialitzades que evolucionen gràcies a les dades generades en les nostres interaccions amb la xarxa i que estan penetrant i modificant el nostre entorn de manera subtil i inadvertida. La intel·ligència artificial està evolucionant cap a un mitjà tan ubic com l’electricitat, ha penetrat en les xarxes socials convertint-se en un agent autònom capaç de modificar la nostra intel·ligència col·lectiva i, a mesura que aquest mitjà s’incorpora a l’espai físic, està modificant la manera en què el percebem i hi actuem. A mesura que aquest nou entramat tecnològic s’aplica a més camps d’activitat, queda per veure si aquesta és una intel·ligència artificial per al bé, capaç de comunicar-se d’una manera eficient amb l’ésser humà i augmentar les nostres capacitats o un mecanisme de control que, alhora que ens substitueix en tasques especialitzades, captura la nostra atenció convertint-nos en consumidors passius.
Algoritmes intel·ligents a la xarxa
A principis d’any, Mark Zuckerberg va publicar la nota Construint una Comunitat Global adreçada a tots els usuaris de la xarxa social Facebook. En aquest text, Zuckerberg acceptava la responsabilitat social d’aquest mitjà, alhora que el definia com un agent actiu en la comunitat global i compromès a col·laborar en la gestió d’emergències, el control del terrorisme i la prevenció del suïcidi. Aquestes promeses radiquen en un canvi en els algoritmes que regeixen aquesta plataforma. Si fins ara la xarxa social filtrava la gran quantitat d’informació pujada a la plataforma recollint dades de les reaccions i els contactes dels seus usuaris, ara el desenvolupament d’algoritmes intel·ligents permet comprendre i interpretar el contingut d’aquestes informacions. D’aquesta manera, Facebook ha desenvolupat l’eina Deep Text, que aplica aprenentatge automàtic per entendre el que els usuaris diuen en els seus posts, i crear models de classificació d’interessos generals. La intel·ligència artificial també es fa servir per a la identificació d’imatges. DeepFace és una eina que permet identificar els rostres en fotografies amb un nivell d’encert proper al dels éssers humans. La visió computeritzada també s’aplica a generar descripcions textuals de les imatges en el servei Automatic Alternative text adreçat a què els invidents puguin saber què estan publicant els seus contactes. Així mateix, ha permès al Connectivity Lab d’aquesta companyia generar el mapa de població més exacte fins ara. En el seu esforç per administrar connexió a la xarxa arreu del món mitjançant drons, aquest laboratori ha analitzat imatges per satèl·lit de tot el globus a la recerca d’edificacions que revelessin presència humana. Aquestes dades, en combinació amb les bases de dades demogràfiques existents, ofereixen informació exacta d’on es localitzen els usuaris potencials de la connectivitat oferta pels drons.
Aquestes aplicacions i moltes més, que la companyia testeja i aplica periòdicament, es basen en el FBLearner Flow, l’estructura que facilita l’aplicació i el desenvolupament d’intel·ligència artificial a tota la plataforma. Flow és un motor automatitzat d’aprenentatge automàtic que permet entrenar fins a tres-cents mil models cada mes, assistit per AutoML, una altra aplicació intel·ligent que neteja les dades perquè siguin emprades en xarxes neuronals. Aquestes eines automatitzen la producció d’algoritmes intel·ligents, que són aplicats a jerarquitzar i personalitzar el mur dels usuaris, filtrar continguts ofensius, ressaltar tendències, ordenar resultats de recerques i moltes altres coses que estan canviant la nostra experiència a la plataforma. La novetat d’aquestes eines és que no només modelen el medi d’acord amb les nostres accions, sinó que, en accedir a la interpretació dels continguts que publiquem, permet a la companyia extreure patrons de la nostra conducta, preveure les nostres reaccions i influir-hi. En el cas de les eines posades a disposició per a la prevenció del suïcidi, actualment consta d’un menú desplegable que permet informar de possibles casos i accedir a informació útil com números de contacte i vocabulari per adreçar-se a la persona en risc de manera adequada. No obstant això, aquests casos reportats formen una base de dades que, analitzada, dóna lloc a patrons de conducta identificables que en un futur proper permetrien a la plataforma preveure una possible incidència i reaccionar-hi de manera automatitzada.
Per la seva banda, Google és la companyia darrere de l’últim gran assoliment de la intel·ligència artificial. Alpha Go està considerat el primer programa d’intel·ligència general. El programa, desenvolupat per Deep Mind, la companyia d’intel·ligència artificial adquirida per Google el 2014, no només empra aprenentatge automàtic que li permet aprendre analitzant un registre de jugades, sinó que, a més, integra aprenentatge reforçat que li facilita elaborar estratègies apreses jugant contra si mateix i en altres jocs. L’any passat aquest programa va guanyar Lee Sedol, el gran mestre de Go, un joc considerat el més complex mai creat per la intel·ligència humana. Aquest fet no només ha contribuït al ressò publicitari que envolta la intel·ligència artificial, sinó que ha col·locat aquesta companyia al capdavant d’aquest nou entramat tecnològic. Google ha liderat els canvis que han marcat l’evolució dels cercadors web, i ara planteja un món d’intel·ligència artificial (AI first world) que canviaria el paradigma que regeix la nostra relació amb aquest mitjà. Aquest canvi es va introduir a la carta adreçada als inversors d’aquest any, la redacció de la qual Larry Page i Sergey Brin han cedit a Sundar Pichai, el CEO de Google, el qual ha introduït l’assistent Google.
Google aplica l’aprenentatge automàtic al seu cercador per autocompletar i corregir els termes de cerca que hi introduïm. Per a aquesta finalitat utilitza el processat de llenguatge natural, tecnologia que també li ha permès desenvolupar el seu traductor i el reconeixement de veu i crear Allo, una interfície conversacional. D’altra banda, la visió computeritzada ha donat lloc al servei de cerca per imatges, i és el que permet a la nova aplicació Google Photos classificar les nostres imatges sense necessitat d’etiquetar-les abans. Altres aplicacions d’intel·ligència artificial permeten a Perspective analitzar i denunciar comentaris tòxics per reduir l’assetjament i abús a la web, i fins i tot reduir el cost energètic de les seves granges de servidors de dades.
L’assistent de Google suposaria una nova manera d’obtenir informació a la plataforma que substituiria la pàgina de resultats de recerca per una interfície conversacional. En aquesta un agent intel·ligent accediria a tots aquests serveis per entendre el nostre context, la situació i les necessitats i elaborar, no pas una llista d’opcions, sinó una acció com a resposta a les nostres preguntes. D’aquesta manera, Google ja no proporcionaria accés a informació sobre un espectacle, els horaris i el lloc d’emissió i venda d’entrades, sinó un servei integrat que compraria les entrades i programaria l’espectacle a la nostra agenda. Aquest assistent podria organitzar la nostra agenda, administrar els nostres pagaments i pressupostos i moltes altres coses que contribuirien a convertir els nostres mòbils en els controls remots de les nostres vides.
L’aprenentatge automàtic se sustenta en l’anàlisi de dades i produeix sistemes autònoms que evolucionen amb l’ús. Aquests sistemes generen el seu propi ecosistema d’innovació en un ràpid avanç que està conquistant tot el mitjà d’Internet. Els algoritmes intel·ligents regeixen el sistema de recomanació de Spotify; és el que permet a l’aplicació Shazam sentir i reconèixer cançons i està darrere de l’èxit de Netflix, que no només els utilitza per recomanar i distribuir els seus productes, sinó també per planejar la seva producció i oferir sèries i pel·lícules al gust dels seus usuaris. A mesura que s’incrementa el nombre de dispositius connectats que generen dades, la intel·ligència artificial s’infiltra a tot arreu. Amazon no només l’empra en els seus algoritmes de recomanació, sinó també en la gestió de la seva logística i en la creació de vehicles autònoms que puguin transportar i lliurar els seus productes i l’aplicació per compartir transport Uber els fa servir per perfilar la reputació dels seus conductors i usuaris, per aparellar-los, proposar les rutes i calcular els preus dins del seu sistema variable. Aquestes interaccions produeixen una base de dades que la companyia està emprant en la producció del seu vehicle autònom.
Els vehicles autònoms constitueixen una altra de les fites de la intel·ligència artificial. Des que el GPS es va implantar en els vehicles el 2001, s’ha produït una gran base de dades de navegació que, juntament amb el desenvolupament de nous sensors, ha fet possible a Google crear un vehicle autònom que ja ha recorregut prop de 500.000 km sense cap accident i que ha anunciat la seva comercialització amb el nom de Waymo.
La intel·ligència artificial també s’implementa en assistents per a les nostres llars, com el Google Home i l’Echo d’Amazon i en dispositius wearables que recullen dades sobre les nostres constants vitals i que, juntament amb la digitalització de les imatges diagnòstiques i els expedients mèdics, està donant lloc a l’aplicació d’algoritmes de predicció i robots destinats a la salut. Així mateix, la multiplicació de càmeres de vigilància i registres policials està conduint a l’aplicació d’algoritmes intel·ligents per a la predicció del crim i la presa de decisions judicials.
Aprenentatge automàtic, el nou paradigma de la intel·ligència artificial
El medi algorítmic en què tenien lloc les nostres interaccions socials s’ha fet intel·ligent i autònom, ha augmentat la seva capacitat de predicció i control de la nostra conducta, al mateix temps que ha migrat de les xarxes socials per estendre’s a tot el nostre entorn. El nou auge de la intel·ligència artificial es deu a un canvi de paradigma que ha portat aquest entramat tecnològic de la definició lògica dels processos intel·lectuals a un enfocament pragmàtic sustentat en dades i que permet als algoritmes aprendre de l’entorn.
Nils J.Nilson defineix la intel·ligència artificial com una activitat dedicada a fer a les màquines intel·ligents, i la intel·ligència com la qualitat que permet a una entitat funcionar de manera apropiada i amb coneixement del seu entorn. El terme intel·ligència artificial el va fer servir per primera vegada John McCarthy a la proposta escrita juntament amb Marvin Minsky, Nathaniel Rochester i Claude Shanon per al workshop de Dartmouth del 1956. Aquest esdeveniment fundacional estava destinat a convocar un grup d’especialistes que investiguessin maneres en què les màquines simulessin aspectes de la intel·ligència humana. Aquest estudi es basa en la conjectura que qualsevol aspecte de l’aprenentatge o qualsevol altra característica de la intel·ligència es poden descriure de forma prou precisa per ser simulada per una màquina. La mateixa conjectura que va portar Alain Turing a proposar el model formal de l’ordinador en el seu article del 1950 Computer machinery and Intelligence. Juntament amb altres precedents, com la lògica booleana, la probabilitat bayesiana i el desenvolupament de l’estadística, es van dur a terme progressos en el que Minsky va definir com l’avanç en la intel·ligència artificial: el desenvolupament de computadors i la mecanització de la resolució de problemes.
Tanmateix, a mitjan anys vuitanta, hi continuava havent un desfasament respecte al desenvolupament teòric de la disciplina i la seva aplicació pràctica, que va provocar la retirada de fons i un estancament conegut com l’«hivern de la intel·ligència artificial». Aquesta situació va canviar amb la difusió d’Internet i la seva gran capacitat per demanar dades. Les dades han permès connectar la solució de problemes a la realitat en un enfocament més pragmàtic i inspirat en la biologia. En aquest, en lloc d’haver-hi un programador que escriu les ordres que portarien a la resolució d’un problema, el programa genera el seu propi algoritme basat en dades d’exemple i el resultat desitjat. En l’aprenentatge automàtic, la màquina es programa ella mateixa. Aquest paradigma s’ha imposat gràcies al gran èxit empíric de les xarxes neuronals artificials que poden ser entrenades amb dades massives i amb computació a gran escala. Aquest procediment es coneix com a aprenentatge profund (deep learning) i consisteix en capes de xarxes neuronals interconnectades que imiten de manera laxa el comportament de les neurones biològiques, substituint les neurones per nodes i les connexions sinàptiques per connexions entre aquests nodes. En comptes d’analitzar un conjunt de dades com un tot, aquest sistema el descompon en les seves parts mínimes i recorda les connexions entre aquestes parts formant patrons que són transmesos d’una capa a la següent, incrementant-ne la complexitat fins a aconseguir el resultat desitjat. D’aquesta manera, en el cas del reconeixement d’imatges, la primera capa calcularia les relacions d’intensitat entre els píxels de la imatge i transmetria el senyal a la capa següent i així successivament fins a produir un output complet, la identificació del contingut de la imatge. Aquestes xarxes poden ser entrenades gràcies a la propagació inversa (back propagation), una propietat que és capaç de relacions calculades d’acord amb una correcció humana fins a aconseguir el resultat desitjat. D’aquesta manera, el gran poder de l’actual intel·ligència artificial és que no s’atura en la definició d’entitats, sinó que desxifra l’estructura de relacions que donen forma i textura al nostre món. Un procés similar s’aplica a la comprensió del llenguatge natural (natural language processing): aquest procediment observa les relacions entre paraules per inferir el significat d’un text sense necessitat de definicions prèvies. Altres camps d’estudi continguts en el desenvolupament actual de la intel·ligència artificial constitueixen l’aprenentatge reforçat (reinforced learning), un procediment que canvia l’enfocament de l’aprenentatge automàtic del reconeixement de patrons en la presa de decisions guiades per la experiència. El crowdsourcing i la col·laboració entre humans i màquines també es consideren part de la intel·ligència artificial i han donat lloc a serveiscom el Mechanical Turk d’Amazon, un servei en què éssers humans etiqueten imatges o textos per ser usats en l’entrenament de xarxes neuronals.
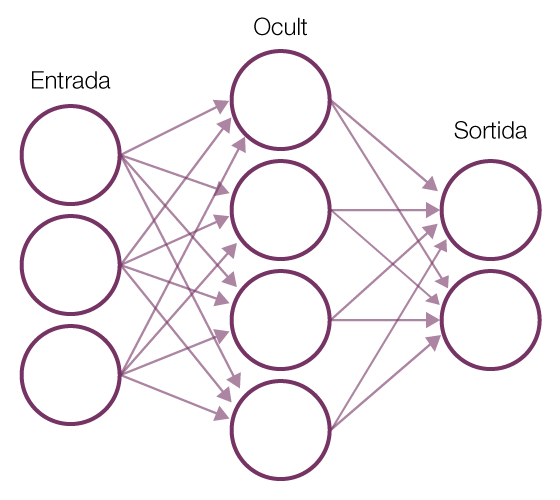
Xarxa neuronal artificial | Viquipèdia
La fragilitat del sistema: la cooperació entre humans i algoritmes intel·ligents
La intel·ligència artificial promet una major personalització i una relació més fàcil i integrada amb les màquines. Aplicada a camps com el transport, la salut, l’educació o la seguretat, es fa servir per vigilar el nostre benestar, alertar de possibles riscos i oferir serveis quan siguin sol·licitats. No obstant això, la implantació d’aquests algoritmes ha donat lloc a alguns esdeveniments escandalosos que han alertat sobre la fragilitat d’aquest sistema. Entre ells l’aparatós accident del vehicle semiautomàtic de Tesla, la difusió de notícies falses en xarxes com Facebook i Twitter, el fracassat experiment del bot Tai desenvolupat per Microsoft i alliberat a la plataforma Twitter per aprendre en interacció amb els usuaris (aquest va haver de ser retirat en menys de 24 hores a causa dels seus comentaris ofensius). L’etiquetatge de persones afroamericanes en Google Photos com a «simis», la constatació que Google és menys propens a mostrar demandes de feina de nivell alt a dones que a homes o que els delinqüents afroamericans són classificats més sovint com a reincidents potencials que els caucasians han mostrat, entre altres problemes, el poder discriminatori d’aquests algoritmes, la seva capacitat de comportaments emergents i la difícil cooperació amb els humans.
Aquests i altres problemes es deuen, d’una banda, a la naturalesa de l’aprenentatge automàtic, la seva dependència del big data, la seva gran complexitat i capacitat de previsió. D’altra banda, a la seva implementació social, on trobem problemes derivats de la concentració d’aquests procediments en unes poques companyies (Apple, Facebook, Google, IBM i Microsoft), la dificultat de garantir un accés igualitari als seus beneficis i la necessitat de crear estratègies de resiliència davant els canvis que es produeixen a mesura que aquests algoritmes van penetrant en l’estructura crítica de la societat.
La falta de neutralitat dels algoritmes es deu a la dependència del big data. Les bases de dades no són neutrals i presenten els prejudicis inherents al hardware amb què han estat recol·lectades, el propòsit per al qual han estat recollides i al paisatge desigual de dades ‒no hi ha la mateixa densitat de dades en totes les zones urbanes ni respecte a tots els estaments i fets socials. L’aplicació d’algoritmes entrenats amb aquestes dades pot difondre els prejudicis presents en la nostra cultura com un virus, i això pot donar lloc a cercles viciosos i a la marginalització de sectors de la societat. El tractament d’aquest problema passa per l’elaboració de bases de dades inclusives i un canvi d’enfocament en l’orientació d’aquests algoritmes cap al canvi social.
El crowdsourcing pot afavorir la creació de bases de dades més justes, col·laborar a valorar quines dades són sensibles en cada situació i procedir a la seva eliminació i a testejar la neutralitat de les aplicacions. En aquest sentit, un equip de les universitats de Columbia, Cornell i Saarland ha elaborat l’eina FairTest, que busca associacions injustes que es poden produir en un programa. D’altra banda, orientar els algoritmes cap al canvi social pot contribuir a la detecció i eliminació dels prejudicis presents en la nostra cultura. La Universitat de Boston, en col·laboració amb el Microsoft Research, ha portat a terme un projecte en què els algoritmes són utilitzats per a la detecció dels prejudicis recollits en la llengua anglesa, concretament les associacions injustes que es donen a la base de dades Word2vec, utilitzada en moltes aplicacions de classificació automàtica de text, traducció i cercadors. El fet d’eliminar els prejudicis d’aquesta base de dades no els elimina de la cultura, però n’evita la propagació per mitjà d’aplicacions que funcionen de manera recurrent.
Altres problemes es deuen a la manca de transparència, que deriva no només del fet que aquests algoritmes són considerats i protegits com a propietat de les companyies que els implementen, sinó de la seva complexitat. No obstant això, el desenvolupament de processos que faci aquests algoritmes explicatius és d’importància cabdal quan aquests s’apliquen a la presa de decisions mèdiques, judicials o militars, on poden vulnerar el dret que tenim a rebre una explicació satisfactòria respecte a una decisió que afecta la nostra vida. En aquest sentit, l’Agència de Recerca per a la Defensa Americana (DARPA) ha iniciat el programa Intel·ligència artificial explicativa (Explainable Artificial Intelligence). Aquest programa explora nous sistemes de coneixement profund que puguin incorporar una explicació del seu raonament, ressaltant les àrees d’una imatge considerades rellevants per a la seva classificació o revelant un exemple de la base de dades que mostri el resultat. També desenvolupen interfícies que facin el procés de l’aprenentatge profund amb les dades més explícites, mitjançant visualitzacions i explicacions en llenguatge natural. Un exemple d’aquests procediments el trobem en un dels experiments de Google. Deep Dream, dut a terme el 2015, va consistir a modificar un sistema de reconeixement d’imatges basat en aprenentatge profund perquè, en lloc d’identificar objectes continguts a les fotografies, els modifiqués. Aquest procés invers permet, a més de crear imatges oníriques, visualitzar les característiques que el programa selecciona per identificar les imatges, mitjançant un procés de desconstrucció que força el programa a treballar fora del seu marc funcional i revelar-ne el funcionament intern.
Finalment, la capacitat de previsió d’aquests sistemes els porta a un increment en la capacitat de control. Són coneguts els problemes de privacitat que deriven de l’ús de tecnologies en xarxa, però la intel·ligència artificial pot analitzar les nostres decisions anteriors i preveure les nostres possibles activitats futures; això dóna al sistema capacitat per influir en la conducta dels usuaris, la qual cosa reclama un ús responsable i el control social de la seva aplicació.
Ex Machina ens ofereix una metàfora de la por que envolta la intel·ligència artificial, que aquesta superi les nostres capacitats i s’escapi del nostre control. La probabilitat que la intel·ligència artificial produeixi una singularitat o un esdeveniment que canviaria el curs de la nostra evolució humana continua sent remota; però els algoritmes intel·ligents de l’aprenentatge automàtic s’estan disseminant en el nostre entorn i produint canvis socials significatius, per la qual cosa cal desenvolupar estratègies que permetin a tots els agents socials entendre els processos que aquests algoritmes generen i participar en la seva definició i implementació.





{kind=link}
Deixa un comentari