
Tightrope performers at 4-H Club fair. Cimarron, Kansas, 1939 | Russell Lee, Library of Congress | Public domain
Digital intelligences are increasingly being used to solve complex issues that were previously decided on the basis of professional expertise. As such, we set out to analyse how humans and machines make decisions and who makes them more fairly depending on the context.
Aixa is a five-year-old girl who is taken into a hospital casualty department by her grandmother. The child shows clear signs of abuse and bruises all over her body. The woman explains to the doctor that she has been beaten by her parents. To establish whether there is a risk of this happening again, and to make sure the child doesn’t receive further beatings, the doctor asks questions about the situation – she must decide whether to refer the child to the social services for legal protection, or send her back home, where the abuse could be repeated. To do this, she is assisted by an artificial intelligence (AI) tool that estimates the seriousness of the case and the precautionary measures based on the answers obtained. If the final decision is that she should be taken away from her parents, Aixa will not go home that night, but will be placed in care and foster homes, where unknown adults will take care of her basic needs for the next few years until the age of 18.
When in 2018 the writer and mathematician Cathy O’Neil visited the CCCB to present her book Weapons of Math Destruction, she posed a question to the audience: “Who would be capable of deciding whether or not a child who has been abused should go back home, with the good intention of protecting her from future abuse?” The audience remained silent, unsure of what to say. “In the US, this is being decided by an algorithm,” she added. At that point, I’m sure a lot of people in the audience were wondering: “But… how can an algorithm know whether the child is going to be hit again before it happens?”. And a few second later, O’Neil herself replied: “It can’t know, but this is what’s happening”.
Three years ago, the question might have seemed provocative and irrelevant, but today such tools operate in most countries unawares to the general public. Professionals in charge of social care cases make complex decisions on a daily basis on a wide range of issues. Before the AI boom, they relied on their own experience built up over the years.
Obviously, they sometimes made the wrong decisions, possibly with serious consequences for the people concerned. Which is why we now hope that intelligent AI systems will help us to improve these decisions. But what happens if the AI tool gives a different result to the specialist – which one will take precedence? If the algorithm decides that Aixa is at high risk but the doctor doesn’t consider it serious enough to separate her from her family, will she dare to send her home?
We know that AI is not perfect and that even the best intelligent system can make mistakes. Which begs the question: how much trust should we place in machines and how much in professional expertise? To find an answer, perhaps we should look at which of the two decisions – human or machine – involves more bias and more noise (i.e. more variance in the decisions). Notwithstanding the human tendency to accept the recommendations of a system that we believe to be intelligent.
Differences between bias and noise
In 2016, the economist Daniel Kahneman – along with other authors – wrote an article entitled “Noise: How to overcome the high, hidden cost of inconsistent decision making”. In the article he explained the difference between “bias” and “noise” through the analogy of throwing darts at four targets. Target A is neither biased nor noisy; target B is only noisy; target C is only biased; and target D is both. The diagram below is based on this idea.
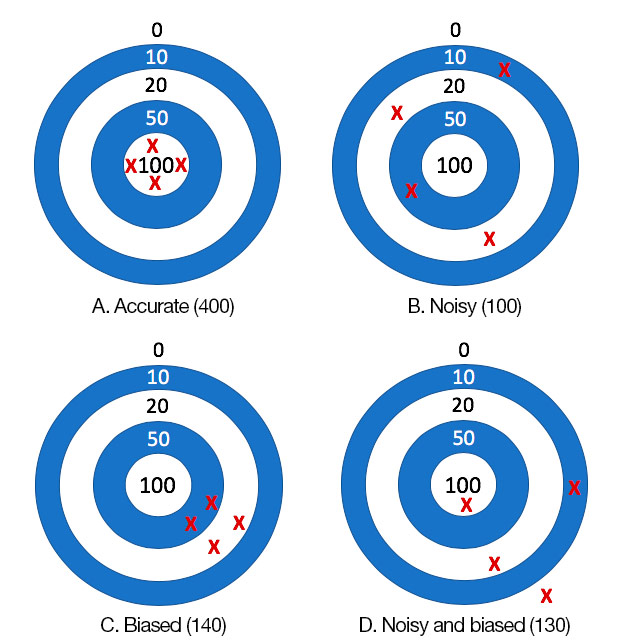
But let’s start from the beginning: what is meant by “bias” and what is meant by “noise”? AI is good at establishing a lot of patterns and relationships, as well as streamlining processes and operations with big data. However, algorithms are not neutral. Neither are the data used to train them, because they have biases. There is no doubt that AI algorithms have biases, but we continue to use them because the benefit or accuracy of the results is considerably greater (by more than 90%) than the harm or error. Biases are similar to prejudices: we all have them, to a greater or lesser degree, and inherit many of them unawares from our social or family environment. The greatest bias is to believe that we have no prejudices at all. However… beware: if biases are not corrected, we run the risk of inhabiting a future in which social progress becomes increasingly difficult due to the perpetuation of prejudices.
Meanwhile, the concept of “noise” could be defined as the different choices that can be made about an action (individual or collective) in a personal or professional situation. When software developers in a company were asked to estimate the time it would take them to perform a given task, their time estimates varied on average by more than 70%. Why, if the task is the same for the same category of professionals in the same company? Often, we make decisions that differ greatly from what our colleagues would make, from our own previous decisions or from those that we claim to follow.
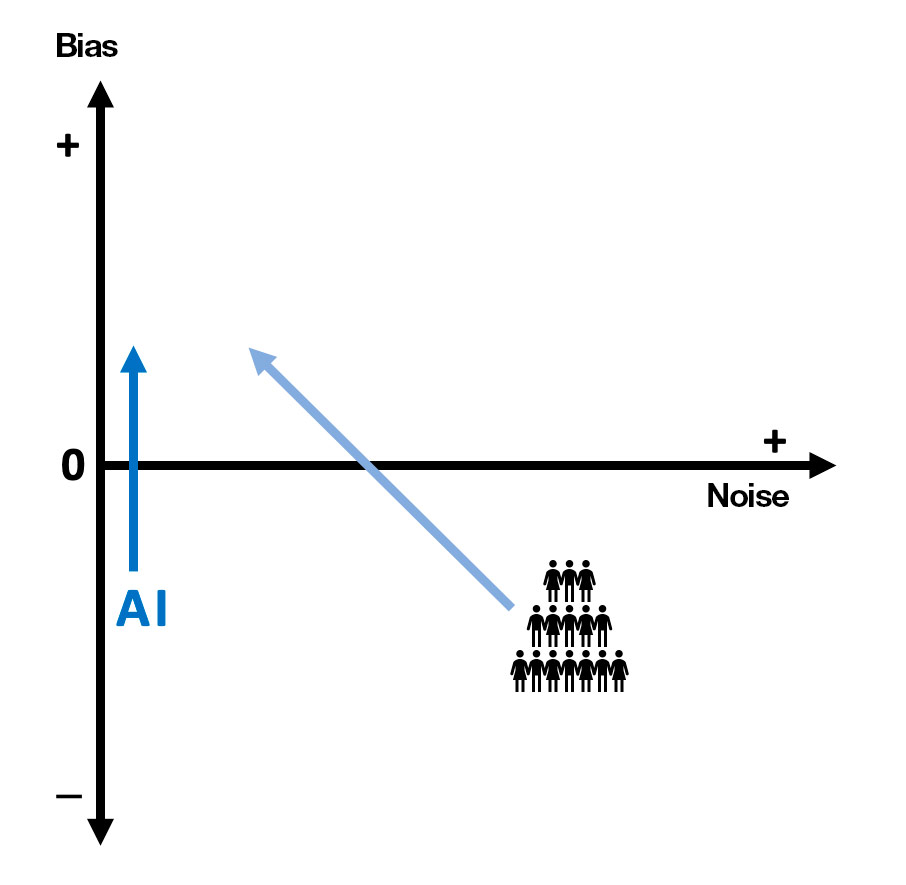
At this point, we should note that AI has biases, but not noise. People, on the other hand, are influenced by both variables.
Noise is easy to perceive
Now let’s return to the targets. If we were to look at them from behind, we would notice that B and D have a higher variability, and we would easily notice the noise. But between A and C it is not so easy to tell which is the biased target. In other words, noise is easy to perceive, while we are not always aware of biases. Most human decisions are noisy, which is why we seek a second medical opinion or hope the judge we are assigned is in a good mood on the day of our hearing. These are two examples of noise at the individual level, but we are also inconsistent over time.
In 2007, Stanford researchers analysed asylum claim decisions in the US and found that one judge approved 5% of claims, while another approved 88% of claims. The two have a very different bias, but the judicial system as a whole appears to be noisy, because the decisions of its judges are inconsistent. Finally, bias can be either negative (male chauvinism) or neutral (gender parity). In the end, it is a question of social consensus.
And how is AI fairer?
A noiseless AI is fairer in the sense that when two cases are the same, its prediction is the same. In other words, if two defendants commit the same crime, their sentences will be the same. But very rarely are cases identical. The paradigm of social injustice through an algorithm was brought to light in 2016 by ProPublica – an independent US newsroom – after it carried out an investigation to demonstrate the bias applied by the COMPAS algorithm to the detriment of black defendants.
AI is noiseless because the algorithms are deterministic. This means that, given a similar input, the outcome will be similar. For example, an air traffic controller may direct air traffic better or worse depending on stress, fatigue or circumstances that affect their mood. In contrast, an intelligent system will always give the same results in the same situation. This cannot be said of judges.
However, AI does have the capacity to be unequal because it learns from the intrinsic biases contained in data. In the working paper “Human Decisions and Machine Predictions”, a group of authors led by the scientist Jon Kleinberg explain how a system trained with New York bail data was racist and slightly amplified the decisions of the most racist judge. This was rather surprising, since the only demographic data it used was the age of the defendant. In other words, racism was encoded in and inferred from criminal records. Despite this, the algorithm was fairer, as it had no noise. By maintaining the same bail rate, it could decrease crime by 25% or, by maintaining the same level of crime, it could grant bail to 42% of defendants who were not previously granted it. Worse still, taking into account the crimes committed, judges granted bail to more than half of the most dangerous 1% of criminals.
However, as ethics expert Lorena Jaume-Palasí would say, justice is actually much more complicated. It may be the case that a judge lets someone walk free in compliance with the law, even when they suspect that there is a high likelihood of their reoffending. “When ruling on a case, justice involves more than simply repeating past decisions. It must be contextualised,” explains Jaume-Palasí. “Because even if the background is similar to other cases, the context may be completely different. Is someone who discriminates consistently but doesn’t consider the specific details of each case more just? If a system reinterprets what the law requires, and judges use a methodology that is the opposite of what is required, that in itself is unfair”.
Positive biases for society
Should we assume that AI will always be biased? Not necessarily. Is it possible for an algorithm to make automated, non-biased decisions for individuals or companies? That will depend on whether the biases are in the data, in the algorithm or in the interaction between the user and the system. Since in practice it is very difficult to have no bias at all, what we need to do is mitigate it. But it will be difficult to eliminate bias, especially when we do not know all the sources. The most important biases are explicit, but many others may be implicit.
Biases can also be positive, meaning they have a positive effect on society. This should be a necessary condition of any algorithm making automated decisions or predictions. For example, the fact that there are more female than male nurses in hospitals could be a positive bias if they were shown to have more empathetic and caring qualities.
Over time, it would be good if AI could help to generate positive biases (the blue vertical arrow in the diagram), and if it were so useful that people could perceive and thus reduce their own biases (diagonal arrow in the diagram). But wouldn’t that be asking too much of this technology? If AI is programmed by people, and we ourselves are not aware of our biases, how can machines possibly pinpoint them for us? Shouldn’t we first change our entire global education system and learn from a young age to identify the most relevant social and cognitive biases?
More humans with more technology
AI generates many misgivings. Its advantages are well known, but so are the risks it entails due to the multitude of errors identified over recent years. One of its greatest challenges is that of explainability, which means understanding how an algorithm has learned automatically and come up with the results, whether in the form of automated decisions or predictions.
Another risk – as artist and researcher Joana Moll mentions in her article “Against Complexity” – is that we are led to believe that any problem can be solved simply by machines. In this regard, it is inevitable that we should wonder about the consequences that this laissez-faire attitude could have for any society. If, for example, Aixa’s doctor were to blindly trust the results of the algorithms at her disposal – overlooking her own intuition gained through professional experience – humans would be totally dependent on machines for any movement, progress or evolution.
But – as we don’t wish to be apocalyptic or to end with a worst-case scenario – we might hope that the most advanced technology will help us to build a future that is increasingly respectful of the rights and values for which we have fought in recent decades. How it could do this is still an unknown. We do not even know if we will succeed. What we can hope for is that AI will get progressively better and that it will complement human knowledge. At the moment, it not only fails to correct our mistakes, but sometimes even magnifies them.






{kind=link}
Leave a comment